El área bajo la curva en una distribución
Supongamos que observamos la distribución normal, como en la figura de abajo. Notaremos algo: la línea que define al área en azul es la función de probabilidad, que describiremos como \(F(x)\).
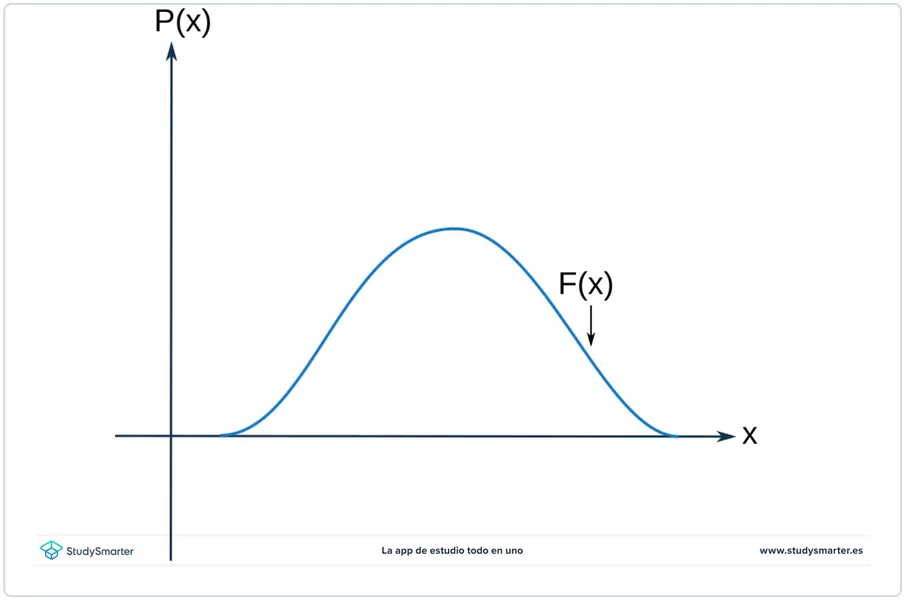
Fig: 1. El área en azul bajo la curva es igual a la probabilidad de la variable en un rango indeterminado \([a, b]\).
Los valores de \(x\) son los valores posibles que una variable puede obtener. Estos, por supuesto, están en un rango definido \([a, b]\), y los puedes ver en el eje \(x\).
Los valores en \(y\) significan la probabilidad que la variable \(x\) que medimos obtenga cierto valor.
El punto medio de la gráfica (en este caso, una campana) es el dato que tiene más probabilidad de ser obtenido.
Hagamos un ejemplo gráfico que explique un poco más lo visto.
Se tiene una escuela a la que alumnos de 6 a 12 años acuden; hay alrededor de 1200 alumnos y su estatura mínima es \(1\text{ m}\) y la máxima es \(1,6\text{ m}\). La estatura media es de \(1,3\text{ m}\), es la estatura que más alumnos reportan y tiene una probabilidad del 15%.
La gráfica siguiente gráfica muestra la distribución de las alturas.
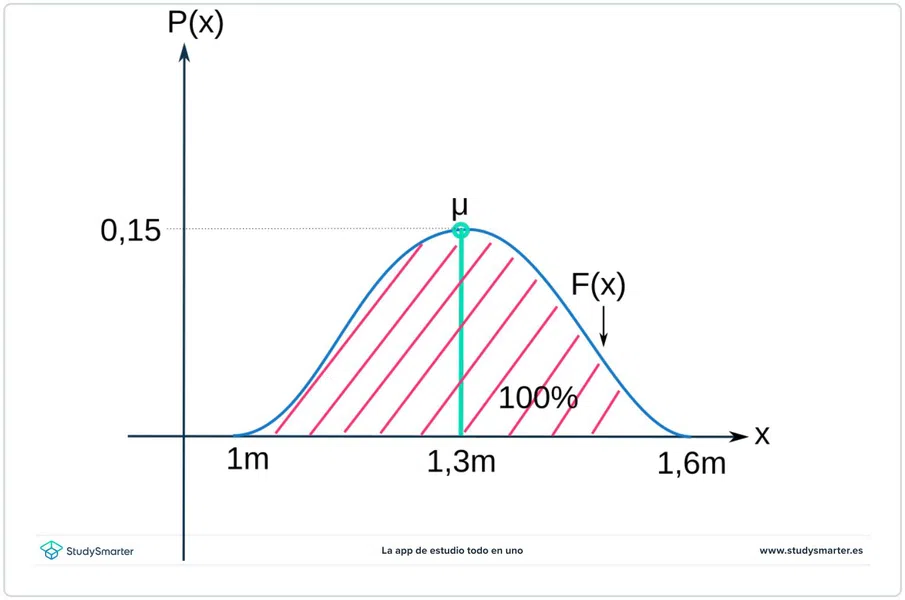
Fig. 2: Distribución de las alturas con un máximo en \(1,3\text{ m}\).
1. Los valores posibles de las estaturas van de \(1\text{ m}\) a \(1,6\text{ m}\), como se puede ver en el eje de las \(x\).
2. Los valores en en el eje de las \(y\) llegan a un máximo de \(0,15\), esto es porque el dato más probable que puede aparecer tiene esa probabilidad y se muestra como el máximo de la función (punto de color cian).
3. Este punto máximo \(y=0,15\) en \(x=1,30\text{ m}\) es la moda y también la media de la distribución.
Hay que añadir un punto extra: si sumamos las probabilidades de todos los puntos abajo de la curva, se obtiene un \(100%\) o uno. Esto se debe a que si una variable aleatoria sucede, su probabilidad total en el rango en el que existe \([a, b]\) debe ser del \(100%\).
Función de densidad y sus propiedades
La función que define la curva se conoce como la función de densidad. Tiene este nombre debido a que no toma un solo valor \(x\) para darnos un valor de la probabilidad \(y\); la función, en cambio define una zona \([a_1, a_2]\) y para esta zona la probabilidad es la suma de las probabilidades entre \(a_1\) y \(a_2\).
De hecho, esto es una sumatoria, si lo ves de este modo:
\[\sum^{a_2}_{a_1}F(x)\]
Debido a que la función \(F\) es continua, esto se puede definir como una integral:
\[P(a_1
Veamos la imagen de abajo:
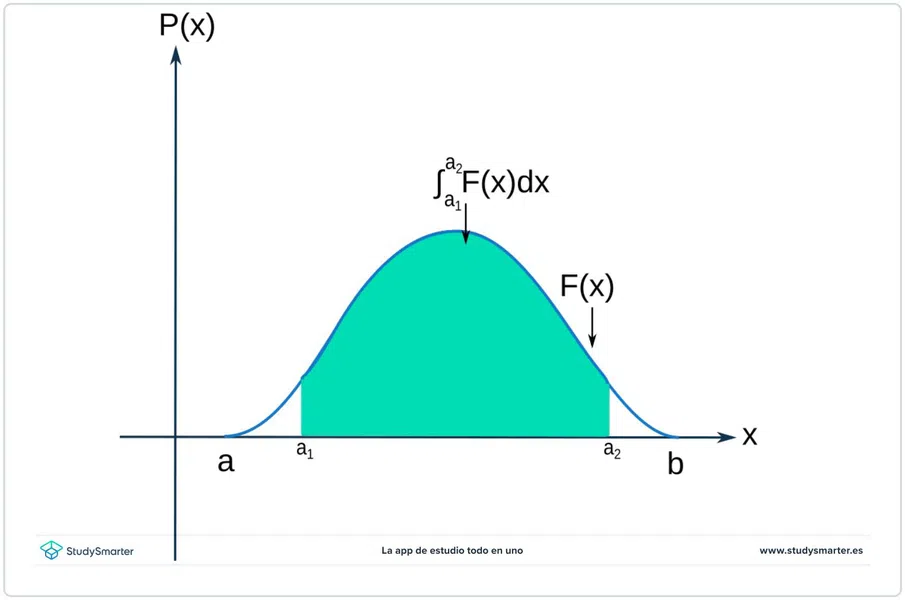
Fig. 3: Función dentro de un intervalo de la distribución; en este intervalo la probabilidad total debe ser menor que el 100%.
Por supuesto, si integramos entre el punto máximo y mínimo de la función, esta integral debe ser igual a \(P=1\).
Características e importancia de la distribución normal
Una de las funciones de densidad más importantes es la función de densidad de la distribución normal.
Muchos fenómenos en el universo siguen una distribución de tipo normal, esta distribución es la que viste en la primera imagen.
Para explicar cómo surge esta distribución, haremos un pequeño ejemplo mental. En este te lo explicaremos usando una función muy simple: \(y=ax\). Después de esto, te explicaremos algunas de sus propiedades.
Supongamos que se tiene una serie de mediciones de un fenómeno físico, y este se puede aproximar fácilmente. Se sabe que los valores \(x\) son parte de un rango \([A, B]\), donde \(x\) puede tomar cualquier valor dentro de este rango.
Pero hay medidas que son más comunes que las otras; de hecho, este fenómeno tiende a darte valores cercanos a un valor central \(m_0\). Supongamos que este valor central aparece el 25% de veces, lo cual se traduce en \(0,25\) en \(N\).
Debido a que \(m_0\) es el valor mayor, las desviaciones que causan mediciones alejadas del valor esperado \(m_0\) —como \(m_1, m_2, m_3, m_4\)— tienen menos repeticiones \(N\); esto se traduce en que esos valores \(x\) son menos probables \(P(x)\).
Esto lo podemos ver en la gráfica siguiente:
 Fig. 4: Mediciones menores, según nos alejamos del valor máximo —que son la moda y la media—.
Fig. 4: Mediciones menores, según nos alejamos del valor máximo —que son la moda y la media—.
Si unimos todas las mediciones y hacemos muchas de estas mediciones, obtenemos una curva en forma de una campana.
El valor central más común se puede denominar \(ax\). Las perturbaciones que causan medidas mayores o menores pueden restarse o sumarse, y se repiten simétricamente en ambos lados. Debido a esto, la probabilidad de obtener una medición mayor como consecuencia de una desviación es, también, menor. Puedes verlo en la imagen a continuación.
 Fig. 5: Perturbaciones causando desviaciones alrededor del valor central y creando la famosa campana de Gauss.
Fig. 5: Perturbaciones causando desviaciones alrededor del valor central y creando la famosa campana de Gauss.
La altura en esta gráfica representa la probabilidad de obtener un valor de \(x\); o, si son valores de mediciones, representa el número de mediciones mayor o o menor que el valor esperado.
Si, como mencionamos, las desviaciones son mayores a medida que nos alejamos del valor mayor de \(x\), lo que se tendría es lo siguiente:
\[x-|d_2|<|x-|d|\]
Esto es porque:
\[|d_2|>|d|\]
En la imagen siguiente, la desviación \(d_2\) produce un número menor que la desviación \(d\), pero la probabilidad de ese valor es menor el de \(d\), \(P(ax-d_2)
El máximo es, de hecho, la medición que se repite más; en este caso, la media \(\mu\).
 Fig. 6: El valor de la probabilidad de obtener un número mayor o menor que \(\mu\) debe de disminuir a medida que nos alejamos de \(\mu\).
Fig. 6: El valor de la probabilidad de obtener un número mayor o menor que \(\mu\) debe de disminuir a medida que nos alejamos de \(\mu\).
Y si estas desviaciones se dan en un rango \([-a, a]\) y la función se puede evaluar en cualquier punto, lo que se tiene es una curva con un máximo en el centro.
Esta curva es conocida como una campana de Gauss y es la forma característica de una distribución normal.
La distribución normal que ves en la gráfica tiene propiedades importantes:
El punto máximo de la curva es la media; es decir, el dato que está a la mitad del rango donde se mide la variable \(x\). Si el rango es \([-2, 2]\), la media estaría en \(x=0\).
El punto máximo es el dato que tiene más probabilidad de aparecer en las mediciones, y tiene por nombre la moda. Debido a esto, la moda y la mediana son el mismo dato.
Como el máximo está a la mitad del intervalo \([-a, a]\), este valor es, también, la media —conocida como \(\mu\)—.
La distribución es simétrica, por lo que si necesitas medir la probabilidad de obtener un valor en el intervalo \([-b, b]\) que está dentro de \([-a, a]\), lo que se tiene que hacer es contabilizar la probabilidad entre la media y \(b\) y multiplicarlo por dos.
Puedes definir la distribución usando dos valores: la media \(\mu\) y su desviación estándar \(\sigma\).
A medida que te alejas del valor central, la probabilidad de los valores tiende hacia cero.
Su función de densidad está dada por la fórmula: \(\dfrac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\).
Como te mencionamos, muchos fenómenos siguen esta distribución, algunos de ellos son:
Sin embargo, esta no es la única distribución de probabilidad; hay otras como:
- Distribución de Poisson.
- Distribución de Rayleigh.
- Distribución Chi cuadrado.
Si quieres saber más acerca de esta distribución, y ver algunos ejemplos, no olvides leer nuestros artículos sobre las distribuciones continuas y la distribución normal.
Función de distribución
La función de distribución es también conocida como la función de distribución acumulada. Como su nombre lo indica esta función nos dice la probabilidad acumulada hasta cierto punto. Observa las siguientes gráficas:
 Fig. 7: Función de densidad
Fig. 7: Función de densidad
 Fig. 8: Función de distribución acumulada.
Fig. 8: Función de distribución acumulada.
La primera corresponde a la densidad de la distribución normal y la segunda, a la función de distribución acumulada. Si observas detenidamente la diferencia principal radica en que en la segunda la suma de la probabilidad aumenta más allá del valor máximo de la media.
Este aumento se debe a que si se tiene un punto \(c\) después de la media, su probabilidad acumulada es la probabilidad desde \(-a\) hasta \(c\). Esto se puede ver en la gráfica de abajo, que expone las áreas.
 Fig. 9: Función de distribución acumulada.
Fig. 9: Función de distribución acumulada.
La fórmula de la función de probabilidad acumulada de la distribución normal con media igual a cero y una desviación estándar igual a uno es:
\[\dfrac{1}{\sqrt{2\pi}}\int^{z}_{-\infty}e^{-\frac{x^2}{2}}dx\]
Es necesario aclarar que cuando se calcula la probabilidad entre el valor de \(-\infty\) a \(z\), lo que se calcula es la probabilidad de que se obtenga un valor menor que \(z\).
Un importante punto a mencionar es que en muchos artículos encontrarás que la fórmula de la distribución normal es igual a:
\[\dfrac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]
En probabilidad, muchas veces deberás integrar estas funciones como:
\[\int^a_a \dfrac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}} dx\]
Estas integrales son complicadas, ya que implican algo llamado función error; aunque aquí no entraremos en explicarla o resolverla, sí podemos mostrarte lo siguiente:
\[\int^{\infty}_{\infty} e^{-a(x^2+b)} dx=\sqrt{\dfrac{\pi}{a}}\]
Debido a que podemos evaluar la integral de la distribución normal en el rango \((-\infty, \infty)\), esperando que las probabilidades fuera del rango \([-a, a]\) sean cero, esta integral nos daría:
\[\int^{\infty}_{-\infty} [\dfrac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}} dx= \dfrac{1}{ \sqrt{2\pi}} \sqrt{2 \pi}\]
Ejercicios distribución normal resueltos
Hagamos unos ejercicios muy simples, con las fórmulas que hemos visto para las funciones de densidad y de distribución acumulada.
Se tiene una función de distribución acumulada con desviación estándar uno y media cero.
Calcula la distribución acumulada entre \(-\infty\) y \(0\).
Solución:
Podemos resolver este problema sin cálculos.
Simplemente: si el total de la probabilidad es \(100\%\), entonces la mitad de la distribución debe ser un \(50\%\).
Se tiene una función de densidad que pertenece a una distribución normal. Su media es cero y su desviación estándar es uno. Obtén la integral que define el área bajo la curva.
Solución:
En este caso debemos integrar la función:
\[\dfrac{1}{\sigma \sqrt{2\pi}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\]
Ya que \(\mu=0\):
\[F(x)=\dfrac{1}{\sigma \sqrt{2\pi}} e^{-\frac{x^2}{2\sigma^2}}\]
Haciendo, además \(\sigma=1\):
\[F(x)=\dfrac{1}{ \sqrt{2\pi}} e^{-\frac{x^2}{2}}\]
Si integramos la función, como vemos en el deep dive, obtenemos:
\[\dfrac{1}{\sigma \sqrt{2\pi}} \sqrt{2 \pi}\]
Esto es, al final:
\[1\]Lo cual significa que el area bajo la curva es uno.
Propiedades de la función densidad y distribución - Puntos clave
- En la función de distribución normal:
- Los valores de \(x\) son los valores posibles que una variable puede obtener. Estos valores, por supuesto, están en un rango definido \([a, b]\); los puedes ver en el eje \(x\).
- Los valores en \(y\) significan la probabilidad de que la variable que medimos \(x\) obtenga cierto valor.
- El punto medio de la gráfica, en este caso una campana, es el dato que tiene más probabilidad de ser obtenido
- La normal no es la única distribución de probabilidad; hay otras como:
- Distribución de Poisson.
- Distribución de Rayleigh.
- Distribución Chi cuadrado.
- La función de distribución también se conoce como la función de distribución acumulada. Como su nombre lo indica, esta función nos dice la probabilidad acumulada hasta cierto punto.





